
> RANTS
This is the place where I share my unfiltered thoughts, late-night musings, and spontaneous brain dumps. No edits, no apologies..
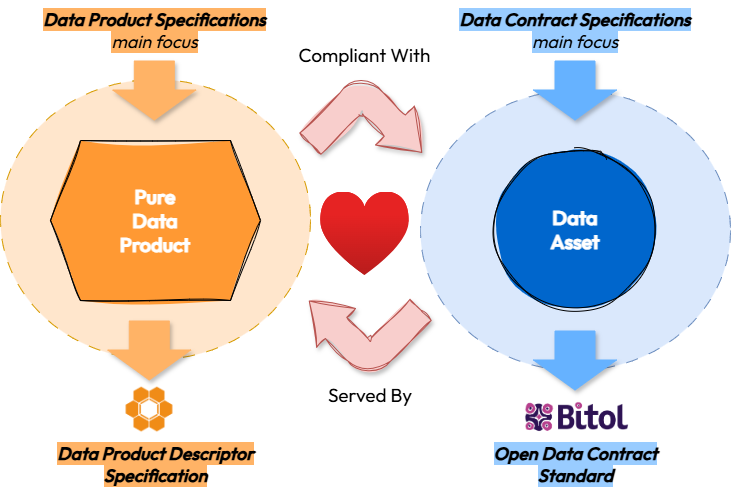
📚 In recent years, several specifications have emerged to define data assets managed as products. Today, two main types of specifications exist:
1️⃣ Data Contract Specification (DCS): Focused on describing the data asset and its associated metadata.
2️⃣ Data Product Specification (DPS): Focused on describing the data product that manages and exposes the data asset.
👉 The Open Data Contract Standard (ODCS) by Bitol is an example of the first specification type, while the Data Product Descriptor Specification (DPDS) by the Open Data Mesh Initiative represents the second.
🤔 But what are the key differences between these two approaches? Where do they overlap, and how can they complement each other? More broadly, are they friends, enemies, or frenemies?
🔎 I explored these questions in my latest blog post. The image below might give away some spoilers, but if you're curious about the full reasoning, read the post.
❤️ I'd love to hear your thoughts!
🔮 It’s difficult to predict, but in my view, consulting won’t disappear—at least not in the medium term. However, the role of consultants will evolve. Rather than delivering prepackaged solutions, their focus will shift toward creating the right environment for making the best decisions, supported increasingly by generative AI and intelligent agents.
⁉️ A consultant’s value will lie more in their ability to ask the right questions than in simply providing answers. They must embrace maieutics as a key approach to gaining a deeper understanding of contexts, identifying problems and priorities, and guiding teams toward shared solutions.
😉 We should prepare for the Consultant Augmented Generation (CAG) era.

😵💫 Enterprise-level data management solutions are complex socio-technical systems. Part of this complexity is essential, meaning it is inherently tied to the functionality the system is designed to deliver and cannot be reduced without compromising its purpose.
📈 In data management, the essential complexity is exceptionally high. The value of data assets grows as they become more interconnected, but these very interconnections create complexity. This complexity increases quadratically with the number of data assets managed. As a result, the more value the solution generates, the more complex it becomes—eventually exceeding the cognitive capacity of the team developing it and causing the system to collapse.
👇 This leads to a Catch-22 paradox...
🔴 "The more successful an enterprise-level data management solution is, the more likely it is to fail."
🤔 Is it possible to escape this paradox? The answer is yes. The key lies in addressing the portion of the system's complexity that is not essential but accidental—complexity that arises from the development approach itself and can be reduced.
🤓 How can this be done? Fortunately, the solution is well-established in all engineering disciplines that deal with complex systems: when a problem is too complex to solve with a single monolithic solution, it should be broken into smaller, autonomous parts. In other words, the power of modularity must be leveraged.
❤️ In data management, this means treating data as products and building data management solutions as a composition of interconnected data products.

👇 In complex environments, multi-agent systems consistently offer clear advantages over monolithic agents:
😵💫 In contrast, monolithic agents often encounter bottlenecks, lack flexibility, and struggle to scale effectively.
👇 To create an organic and integrated ecosystem of autonomous agents—rather than falling into an "agentic mess"—it’s crucial to follow some key principles:
😊 If you work with data, these principles will probably sound very familiar!

🚮 In data management, creating excess "stock" is simply wasteful.
👍 This holds true even when adopting a modular approach centered on managing data as a product. Too often, I see organizations measuring the success of their data initiatives by the sheer number of data products they’ve developed, regardless of whether they truly support meaningful use cases.
🛑 Having data products that serve no use case is pointless. Likewise, products that mostly support just one use case are not much better—it’s a clear sign that the integration effort isn’t being reused effectively.
👇 The focus should instead be on a value-driven approach: 1️⃣ Develop data products only when there’s a clear business case for them 2️⃣ Design data products to be flexible enough to support both immediate and future use cases
This value-driven approach is the only way to gradually build composable data architectures where one plus one is greater than two.

👉 The Data Product Dichotomy
👇 Data products can be divided into two categories:
1️⃣ Pure Data Products, aimed at facilitating access to the data they manage,
2️⃣ Analytical Data Products, designed to deliver functionality based on the data they handle.
🤓 In a pure data product, the more visible and easier the data is to consume (overt data), the higher the product's value. In an analytical application, the opposite is true: the less visible the data (covert data), the more valuable the product becomes.
🤔 Here’s the catch: the end user rarely needs the data. What they need are decisions supported by the data. So why does it still make sense to consider products where data is overt, like pure data products, as valuable? Can't we focus solely on products where data is covert, like analytical data products?
😉 My answer is in the resources

👉 A data product is a product that facilitates an end goal through the use of data.
📕 This is how DJ Patil defines a data product in his book "Data Jujitsu: The Art of Turning Data into Product."
🤔 While it’s a definition that makes sense, it feels rather broad—perhaps too broad to be genuinely actionable. After all, nearly every software application leverages data to deliver its functionalities. So, what truly sets a data product apart?
👇 In a recent blog post (link in the comments), I shared my perspective on what I mean when I talk about data products.
❓ Does it resonate with you? How have you defined the concept of a data product within your organization?
